
RIPPLE JOIN
|
RIPPLE JOIN |
![]()
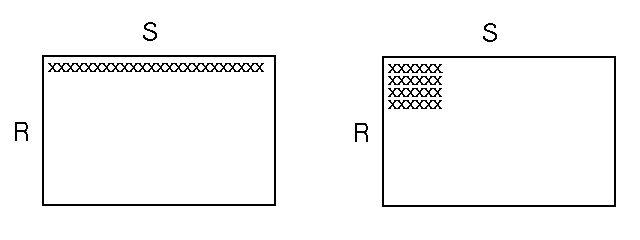
| RIPPLE Join: Rectangles of Increasing Perimeter Length
The traditional goal for join algorithms is to minimize the completion time. In contrast, the goal of online queries is to maximize the rate at which the confidence interval decreases. We have developed a family of Ripple Join algorithms, which improve the rate at which the confidence interval decreases for multi-table aggregation queries, and simultaneously provide updated estimates to the display in a timely fashion. The central idea of Ripple Join comes from the fact that in order to generate a new confidence interval, a sample of one input relation must be fully joined with a sample of another input relation. To achieve this as quickly as possible, the ripple join alternates fetching from each of its input relations. When it fetches a new tuple from one relation, that tuple is combined with all previously seen tuples from the other relation. The ratio at which the join fetches from the two relations is critical to performance, and can be determined and modified dynamically by observing the statistical properties of the sets of tuples seen so far. |
 |
|
The image above demonstrates the difference between Ripple Join (right) and Nested Loops Join (left). The X's correspond to tuples processed in the join matris. |
Send mail to control@postgres.berkeley.edu
with questions or comments about this web site.
|