Online Permuted Retrieval Of Data From Large Datasets
|
Online Permuted Retrieval Of Data From Large Datasets |
| Many time-consuming data processing applications are more usable when
they are interactive. Rather than making the user wait for a long time
to get an accurate result, she must be allowed to guide the processing
based on intermediate, approximate estimates. In this project we aim to
give the user dynamic control over the rates at which different data items
are processed, based on her relative interest in each. We permute the data
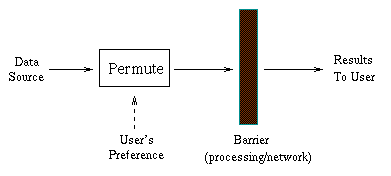
before processing, so that the interesting items cross the barrier first
(Figure 1). This barrier could be complex processing, or a slow network.
An immediate application of our work is in Online Aggregation, where the barrier is typically a time-consuming relational operation such as a multi-table join. Here, the input is divisible into groups and "interestingness" is defined at the granularity of a group, over which an aggregate is being computed. The user can dynamically indicate her interest in a group by specifying a numerical preference which determines the rate at which items for that group are processed. Thus, results for the more interesting groups are updated faster. Here is a motivating example. We have designed a two-phase algorithm for this problem which overlaps the permutation with the processing, so that the permutation is done "on the fly", without any pre-processing. We have also developed some natural performance goals and "interestingness" metrics for such permutation, which use dynamically specified preferences for different groups of data items to decide which item is most interesting at any given moment. We have implemented our work in the context of Online Aggregation in the Informix Universal Server. Preliminary experiments show that our approach is very responsive to dynamic changes in preference, even under highly skewed input distributions such as the Zipfian. We are also investigating the extension of our approach to handle GUI widgets like listboxes over large data sets. Here the barrier is a slow network between the user and the data source, and we want to send over to the user only what she is interested in.
|